鸢尾花分类
1. 数据集介绍
鸢尾花(iris)数据集是一种经典的多元数据集,由英国统计学家Ronald Fisher于1936年收集整理。该数据集包含了150个样本,每个样本包含了4个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)和1个类别信息(三种鸢尾花的类别)。我们尝试使用简单的量子机器学习网络对iris进行分类。首先导入需要的包,这里使用pytorch作为后台。
from isqpy import IsqCircuit
from isqpy.backend import TorchBackend
from isqpy.neural_networks import TorchLayer
import numpy as np
import torch
import torch.nn as nn
from torch.autograd import Variable
import random
import tqdm
import matplotlib.pyplot as plt
from sklearn import datasets, model_selection, preprocessing
from sklearn.metrics import roc_curve, auc
def setup_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
setup_seed(217)
对于iris数据集,我们取出前两个特征(花萼长度、花萼宽度),做出散点图。可以看出对于三种不同的花,其特征还是有明显区别的。
2. 数据集初步可视化
iris = datasets.load_iris()
X = iris.data[:, :2] # take the first two features
y = iris.target
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
# Plot the training points
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1, edgecolor="k")
plt.xlabel("Sepal length")
plt.ylabel("Sepal width")
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)

我们正式开始使用量子机器学习的方法对三种不同品种的鸢尾花进行分类。首先我们取出鸢尾花的特征和对应的标签。我们尝试使用旋转门对鸢尾花的特征进行编码,我们对特征的范围做了变换,使其数值在(-pi,pi)这个区间。我们将整个数据集进行划分,得到训练集和验证集。
3. 数据预处理
X = iris['data']
y = iris['target']
names = iris['target_names']
feature_names = iris['feature_names']
# Scale data to have mean 0 and variance 1
scaler = preprocessing.MinMaxScaler(feature_range=(-np.pi, np.pi))
X_scaled = scaler.fit_transform(X)
4. 数据集加载
# Split the data set into training and testing
X_train, X_test, y_train, y_test = model_selection.train_test_split(
X_scaled, y, test_size=0.2, random_state=2)
创建量子电路iris.isq。对于鸢尾花的4种特征(inputs),我们使用了4个量子比特,每个量子比特一个旋转门进行编码。随后使用三块旋转电路构建参数化电路(weights),最后测量前三个量子比特得到测量结果,测量结果为8维的数组,分别对应三个量子比特所以的状态(000,001,010,011,100,101,110,111)。在得到测量结果后,我们对结果做了一定的处理。我们将8维数组种的3个提取出来,组成一个3维数组,然后使用softmax函数。
根据circuit,我们创建了qnn。除了传入weights的数目(4层旋转,每层8个weights参数)之外,我们还使用了vmap方法。使用vmap时制定了in_dims=(0, None),这表示对应circuit的第一个参数inputs的第一位(dim=0)使用向量化运算,第二个参数weights不使用向量化运算,这与神经网络运行时的batch模式相符合。
随后我们指定了Adam优化器,交叉熵函数为损失函数。
5. 构建量子机器学习网络
iris.isq文件如下。
import std;
param inputs[], weights[];
qbit q[4];
procedure single_h(qbit q[]) {
for i in 0:q.length {
H(q[i]);
}
}
procedure adjacent_cz(qbit q[]) {
for i in 0:q.length-1 {
CZ(q[i], q[i+1]);
}
}
procedure encode_inputs(qbit q[], int start_idx) {
for i in 0:q.length {
Rz(inputs[i+start_idx], q[i]);
}
}
procedure encode_weights(qbit q[], int start_idx) {
for i in 0:q.length {
Ry(weights[i+start_idx], q[i]);
}
for i in 0:q.length {
Rx(weights[i+start_idx+4], q[i]);
}
}
procedure main() {
single_h(q);
encode_inputs(q, 0);
adjacent_cz(q);
encode_weights(q, 0);
adjacent_cz(q);
encode_weights(q, 8);
adjacent_cz(q);
encode_weights(q, 16);
adjacent_cz(q);
encode_weights(q, 24);
adjacent_cz(q);
M(q[0]);
M(q[1]);
M(q[2]);
}
使用python构建机器学习网络。
backend = TorchBackend()
qc = IsqCircuit(
file="iris.isq",
backend=backend,
sample=False,
)
def circuit(inputs, weights):
param = {
"inputs": inputs,
"weights": weights,
}
result = qc.measure(**param)
feature1 = result[0].view(-1)
feature2 = result[3].view(-1)
feature3 = result[7].view(-1)
features = torch.cat((feature1, feature2, feature3))
return torch.softmax(features, dim=0)
qnn = TorchLayer(
circuit=circuit,
num_weights=32,
is_vmap=True,
in_dims=(0, None),
)
optimizer = torch.optim.Adam(qnn.parameters(), lr=0.01)
loss_fn = nn.CrossEntropyLoss()
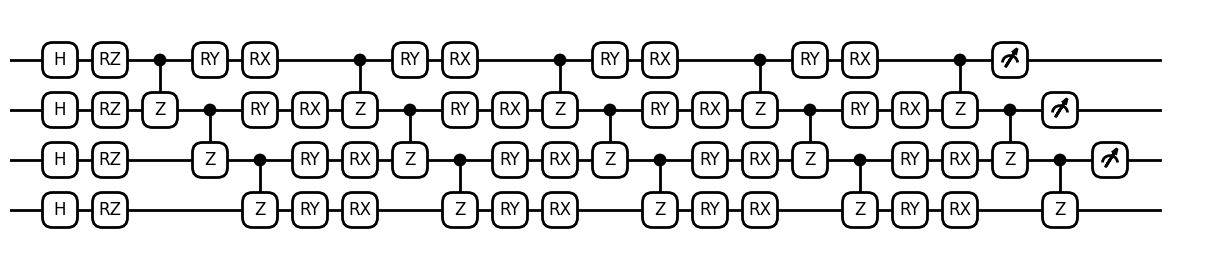
电路可视化。
from isqpy.draw import Drawer
dr = Drawer()
dr.plot(qc.qcis)
6. 训练
对于该量子神经网络,我们尝试训练1000个epochs。由于vmap向量化的加持,一次可以训练整个数据集(即batch=150)。训练的部分细节请参考pytorch的教程。我们保存了整个训练过程中验证集的损失和准确度。
epochs = 1000
X_train = Variable(torch.from_numpy(X_train)).float()
y_train = Variable(torch.from_numpy(y_train)).long()
X_test = Variable(torch.from_numpy(X_test)).float()
y_test = Variable(torch.from_numpy(y_test)).long()
loss_list = np.zeros((epochs,))
accuracy_list = np.zeros((epochs,))
for epoch in tqdm.trange(epochs):
y_pred = qnn(X_train)
loss = loss_fn(y_pred, y_train)
# Zero gradients
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.no_grad():
y_pred = qnn(X_test)
loss = loss_fn(y_pred, y_test)
loss_list[epoch] = loss.item()
correct = (torch.argmax(y_pred, dim=1) == y_test).type(torch.FloatTensor)
accuracy_list[epoch] = correct.mean()
100%|██████████| 1000/1000 [00:36<00:00, 27.12it/s]
7. 模型验证
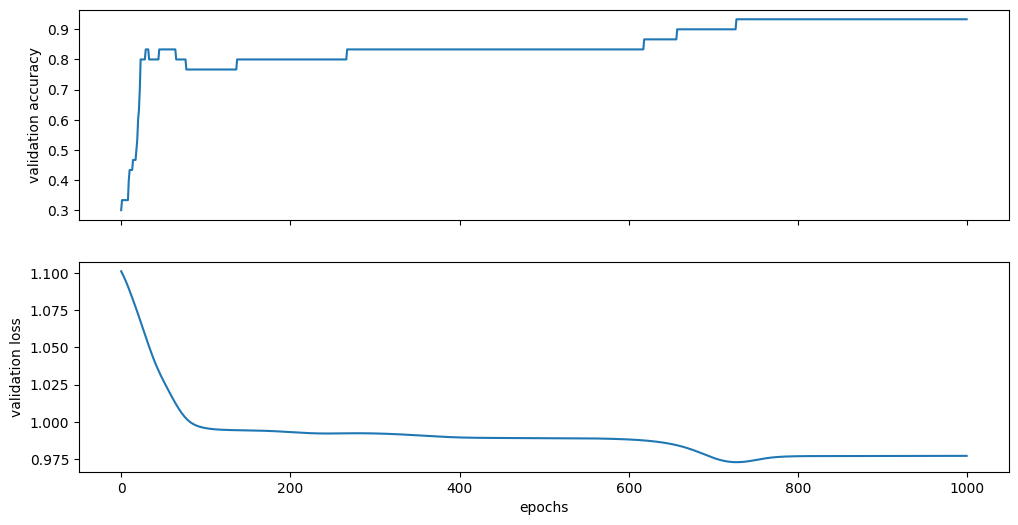
训练完成后,通过作图得到验证集最后的准确度和损失。可以看到准确度达到93%,得到了较好的分类结果。
print("Final validation accuracy:", accuracy_list[-1])
print("Final validation loss:", loss_list[-1])
_, (ax1, ax2) = plt.subplots(2, figsize=(12, 6), sharex=True)
ax1.plot(accuracy_list)
ax1.set_ylabel("validation accuracy")
ax2.plot(loss_list)
ax2.set_ylabel("validation loss")
ax2.set_xlabel("epochs")
Final validation accuracy: 0.9333333373069763
Final validation loss: 0.9770382046699524
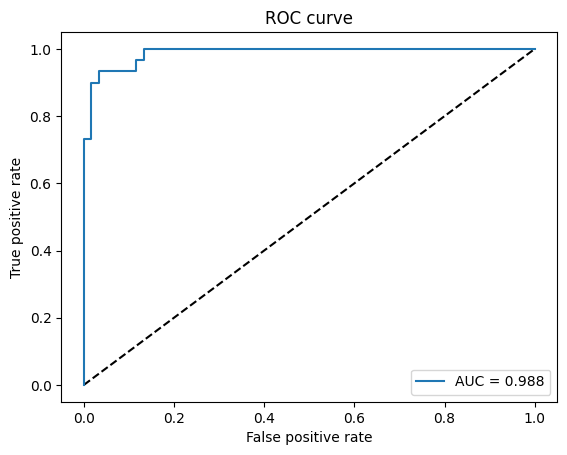
最后可以通过ROC曲线判断模型好坏。
plt.plot([0, 1], [0, 1], 'k--')
# One hot encoding
enc = preprocessing.OneHotEncoder()
Y_onehot = enc.fit_transform(y_test[:, np.newaxis]).toarray()
with torch.no_grad():
y_pred = qnn(X_test).numpy()
fpr, tpr, threshold = roc_curve(Y_onehot.ravel(), y_pred.ravel())
plt.plot(fpr, tpr, label='AUC = {:.3f}'.format(auc(fpr, tpr)))
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC curve')
plt.legend()