量子机器学习基础
1. 使用pytorch后台模拟器
isq模拟器使用pytorch作为后台,能够轻松实现量子机器学习任务的模拟。
首先导入必要的包,为了保证实验的可重复性,我们将随机种子固定。
from isqpy import IsqCircuit
from isqpy.backend import TorchBackend
from isqpy.neural_networks import TorchLayer
import numpy as np
import torch
import torch.optim as optim
import random
def setup_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
setup_seed(222)
2. 定义param变量实现自动微分
对于量子机器学习任务,我们需要在isq文件中定义参数化变量数组,使用param inputs[], weights[];。我们建议定义两个变量,如果需要多个参数变量,可能需要自行实现TorchLayer或者TorchWrapper中间关于参数求导的部分。目前在isq定义的param目前支持RX、RY和RZ三种旋转门。
具体的定义方式请参照下面的isq文件,文件命名为nn_basic.isq。
import std;
param inputs[], weights[];
qbit q[4];
int pauli_inx[] = {2, 2, 3, 3}; // this means Z0Z1I2I3
// using arrays for pauli measurement,
// X:0, Y:1, Z:2, I:3
procedure single_h(qbit q[]) {
for i in 0:q.length {
H(q[i]);
}
}
procedure adjacent_cz(qbit q[]) {
for i in 0:q.length-1 {
CZ(q[i], q[i+1]);
}
}
procedure encode_inputs(qbit q[], int start_idx) {
for i in 0:q.length {
Rz(inputs[i+start_idx], q[i]);
}
}
procedure encode_weights(qbit q[], int start_idx) {
for i in 0:q.length {
Ry(weights[i+start_idx], q[i]);
}
for i in 0:q.length {
Rx(weights[i+start_idx+4], q[i]);
}
}
procedure pauli(int puali_idx[], qbit q[]) {
for i in 0:q.length {
if (puali_idx[i] == 0) {
H(q[i]);
M(q[i]);
}
if (puali_idx[i] == 1) {
X2P(q[i]);
M(q[i]);
}
if (puali_idx[i] == 2) {
M(q[i]);
}
if (puali_idx[i] == 3) {
continue;
}
}
}
procedure main() {
single_h(q);
encode_inputs(q, 0);
adjacent_cz(q);
encode_weights(q, 0);
adjacent_cz(q);
encode_weights(q, 8);
adjacent_cz(q);
encode_weights(q, 16);
adjacent_cz(q);
pauli(pauli_inx, q);
}
对于量子机器学习模拟任务,我们强烈推荐使用Pytorch作为模拟后台。Pytorch支持自动微分,可以很方面的求得参数电路的导数;支持并行和GPU加速,计算效率很高;使用torch.vmap(Pytorch版本大于2.0),可以方便地批量模拟电路,效率高于简单的for循环。
backend = TorchBackend()
qc = IsqCircuit(
file="nn_basic.isq",
backend=backend,
sample=False,
)
电路可视化。
from isqpy.draw import Drawer
dr = Drawer()
dr.plot(qc.qcis)
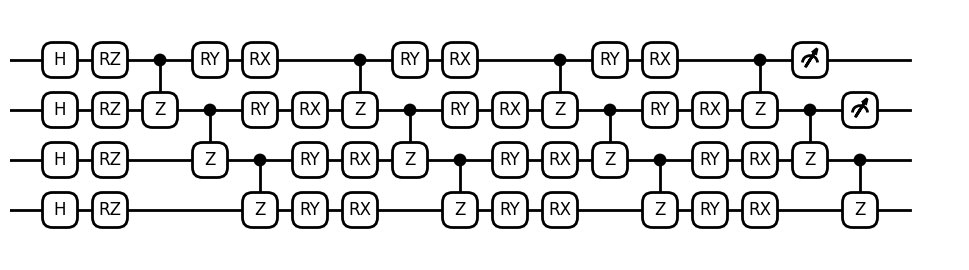
3. 创建量子电路
为了创建量子机器学习的量子电路,我们首先需要定义一个函数,下面以circuit函数为例。
该函数接受两个参数,分别是inputs和weights。其中inputs表示需要编码的数据。电路模拟测量使用pauli_measure()方法。使用pauli_measure()方法时,需要在isq文件中做基变换,我们已经在nn_basic.isq给出了基变换的例子procedure pauli(int puali_idx[], qbit q[])。对于高阶用户可以自行定于测量方式。当使用参数电路时,我们需要使用key-value的形式进行参数的传递。这里的**param将python的字典解包,等价于key-value参数形式。其中key需要与电路中nn_basic.isq中的param inputs[], weights[]相对应,value与传入的参数,即def circuit(inputs, weights)中的inputs, weights相对应。
def circuit(inputs, weights):
param = {
"inputs": inputs,
"weights": weights,
}
return qc.pauli_measure(**param)
4. 正向测量电路
使用pytorch作为模拟后台的时候,我们将参数定义为torch.Tensor。
这里我们随机生成inputs和weights,并将其传给circuit函数,可以得到pauli测量的结果。
inputs = torch.randn(4)
weights = torch.randn(24)
weights_backup = weights.clone()
inputs_backup = inputs.clone()
print(f"{inputs=}")
print(f"{weights=}")
print("Result:", circuit(inputs, weights))
inputs=tensor([-0.4248, 1.1523, -2.1342, 0.5376])
weights=tensor([ 0.3889, -0.7956, -0.4133, -0.2245, -1.3118, 0.4663, -0.9789, 1.3999,
1.6718, 0.1663, -0.4762, -1.0917, 0.5813, -0.1228, -0.0768, -0.7945,
-0.8038, -0.1344, -0.9184, -0.3778, 0.4568, 0.7652, 0.4885, -2.1489])
Result: tensor(-0.1275)
5. 创建量子机器学习层
使用TorchLayer,传入刚才定义好的电路函数以及一些必要的参数,可以返回一个继承于torch.nn.Module的对象qnn。is_vmap为False表示不使用vmap的方法,num_weights代表传入参数weights的长度,initial_weights可以传入自定义的weights初始化数值,如果不传入则会自动初始化参数。我们可以比较circuit和qnn的运行结果,注意参数传递的区别,可以发现由于torch.nn.Module的作用,梯度信息被自动构建。
qnn = TorchLayer(
circuit=circuit,
is_vmap=False,
num_weights=24,
initial_weights=weights,
)
print(qnn)
print(qnn.__class__.__bases__)
print()
print("Run circuit:", circuit(inputs, weights))
print("Run qnn:", qnn(inputs))
TorchLayer(num_weights=24, is_vmap=False)
(<class 'torch.nn.modules.module.Module'>,)
Run circuit: tensor(-0.1275)
Run qnn: tensor(-0.1275, grad_fn=<DotBackward0>)
6. 优化量子电路
因为qnn继承了torch.nn.Module功能,所以我们可以很方便使用pytorch的优化器对其进行优化。我们尝试使用SGD(梯度下降方法),在inputs不变的情况下,更新weights,最小化qnn的返回值,也就是Pauli测量的返回值。经过了50轮的优化,最终可以Pauli测量的最小返回值为-1。
optimizer = optim.SGD(qnn.parameters(), lr=0.05)
for i in range(50):
measurement = qnn(inputs)
measurement.backward()
optimizer.step()
optimizer.zero_grad()
if i % 5 == 0:
print(measurement)
tensor(-0.1275, grad_fn=<DotBackward0>)
tensor(-0.3230, grad_fn=<DotBackward0>)
tensor(-0.4942, grad_fn=<DotBackward0>)
tensor(-0.6281, grad_fn=<DotBackward0>)
tensor(-0.7245, grad_fn=<DotBackward0>)
tensor(-0.7911, grad_fn=<DotBackward0>)
tensor(-0.8372, grad_fn=<DotBackward0>)
tensor(-0.8697, grad_fn=<DotBackward0>)
tensor(-0.8935, grad_fn=<DotBackward0>)
tensor(-0.9115, grad_fn=<DotBackward0>)
可以打印优化后的inputs和weights。inputs作为初始参数在整个优化过程中没有发生变化,weights逐渐被优化到了最优参数,使得pauli测量值趋近-1。
print(f"{inputs}")
print(f"{inputs_backup}")
print("Optimized weights:", weights)
print(f"{weights_backup=}")
tensor([-0.4248, 1.1523, -2.1342, 0.5376])
Optimized weights: tensor([ 0.3963, -0.4383, -0.5218, -0.2149, -1.5535, 1.0736, -0.9547, 1.4377,
2.3391, -0.0104, -0.1606, -1.0917, 0.4081, -0.2264, -0.2291, -0.7945,
-1.0293, -0.6749, -0.9184, -0.3778, 0.4045, 0.9554, 0.4885, -2.1489])
weights_backup=tensor([ 0.3889, -0.7956, -0.4133, -0.2245, -1.3118, 0.4663, -0.9789, 1.3999,
1.6718, 0.1663, -0.4762, -1.0917, 0.5813, -0.1228, -0.0768, -0.7945,
-0.8038, -0.1344, -0.9184, -0.3778, 0.4568, 0.7652, 0.4885, -2.1489])